Oriol Camps, ocamps.n@catradio.com
Llu�s de Yzaguirre, lluis.deyzaguirre@upf.edu
Anna Matamala, anna.matamala@iula.upf.es |
comunicaci� presentada a 1. Freiburger Arbeitstagung zur Romanistischen Korpuslinguistik, Freiburg, 6-8 octubre i publicada a a PUSCH, Claus D. / RAIBLE, Wolfgang (Hrsg.) 2002: Romanistische Korpuslinguistik - Korpora und gesprochene Sprache / Romance Corpus Linguistics - Corpora and Spoken Language (= ScriptOralia; 126). T�bingen: Narr. 500 pp. ISBN 3-8233-5436-1. |
DOPO: un outil
d�analyse orthologique
0. Pr�sentation
Le DOPO (Diagnostic Orthologique Par Ordinateur) est un
syst�me de d�tection d�incidences orthologiques � l�aide de l�ordinateur, bas�
sur la synchronisation des fichiers de voix et de texte. Ce syst�me est en
train d��tre d�velopp� en collaboration entre l�Universit� Pompeu Fabra de
Barcelone et Catalunya R�dio, qui va en �tre l�usager principal quand le
syst�me deviendra suffisamment op�rationnel.
1. Catalunya
R�dio: l�usager principal
Cr��e en 1983, par une loi de Catalogne, Catalunya R�dio a
pour but principal de contribuer � la �normalisation� linguistique,� processus qui a pour but de mettre la langue
catalane en conditions de survivre dans son espace historique, qui a �t�
occup�, sp�cialement dans les usages publics, par l'espagnol ou le fran�ais.
� l'�poque de sa cr�ation, Catalunya R�dio a ouvert un
espace de communication en catalan, puisqu�� ce moment l� il n'y avait pas de
postes de radio en catalan, � l�exception de quelques uns qui n'arrivaient pas
� couvrir tout le territoire ni toutes les heures du jour et de la semaine.
� pr�sent, notre premi�re station de radio poss�de une audience
moyenne de 590.000 auditeurs environ, et elle est leader de la radio
conventionnelle en Catalogne, � plus de 100.000 auditeurs de distance de la
suivante. Nous avons aussi un canal exclusivement informatif, Catalunya
Informaci�, �galement leader dans son genre, avec 67.000 auditeurs, et deux
autres stations: Catalunya M�sica (musique classique), et Catalunya Cultura qui
explore les possibilit�s de la radio en ce qui concerne les th�mes de� culture, en �vitant� la politique et le sport.
Actuellement, on peut dire qu'il existe un espace catalan de
communication, au moins dans la radio, comme le prouve le fait que depuis un
an, divers entrepreneurs priv�s se sont engag�s dans la cr�ation de postes de
radio parlant en catalan, d'abord sp�cialis�s en musique pop-rock et peu apr�s
(septembre 2000) g�n�ralistes.
Une fois �tabli cet espace de communication, il reste
cependant aux moyens de communication publics l�importante mission d'�tre
leaders de la qualit� des programmations, et notamment de la qualit� linguistique.
Cette mission d�rive du fait que le financement (m�me s�il n�est que partiel)
provienne du budget du gouvernement autonome. En effet, une des fonctions des
moyens de communication de masse (mcm) est d'�tablir, de conserver, d��largir
et de diffuser la langue standard par son usage.
Toutefois, les conditions dans lesquelles la qualit�
linguistique des �missions doit �tre maintenue ne sont pas favorables, compte
tenu de la pression que l'espagnol et d�autres langues exercent sur la n�tre.
Il faut remarquer que presque toutes les entr�es d'information se font en
espagnol, fran�ais ou anglais, et que seules les nouvelles locales arrivent aux
m�dias en catalan. Dans le travail des journalistes et des r�dacteurs se
produit donc, un incessant contact de langues, qui d�rive de la nature m�me de
la t�che informative, ainsi que de la situation de double officialit�
linguistique.
Cela signifie que nous ne pouvons pas penser au maintien de
la qualit� sans le travail de quelques professionnels linguistes (correcteurs,
orthologues) qui essaient de compenser cette pression des autres langues.
Cela signifie �galement que ces derniers doivent veiller sur
l'introduction de mots �trangers et m�me de fa�ons de dire import�es qui ne
sont pas n�cessaires, et qu�ils doivent aussi contr�ler la prononciation en
antenne, et non pas seulement dans une vari�t� du catalan, mais, dans les deux
vari�t�s principales (orientale et occidentale) et en respectant quelques
sous-vari�t�s.
Cela signifie encore que, malgr� le progr�s du catalan dans
l'enseignement (qui pr�tend former des citoyens en th�orie parfaitement
bilingues), il faut mettre en oeuvre une s�lection linguistique rigoureuse du
personnel qui va pr�ter sa voix � la radio.
M�me
si une partie importante du travail consacr� � la qualit� linguistique est
effectu�e dans la phase �crite des textes diffus�s (correction de textes avant
leur lecture en antenne), il reste le travail de contr�le de la qualit� de la
langue effectivement utilis�e dans les �missions, et l�obligatoire s�lection du
personnel. Ce travail d��coute de la radio, ou d'un enregistrement, ou de
l��preuve d�un candidat� journaliste de
radio dans le but de d�tecter des erreurs de prononciation, doit �tre fait �
l'oreille. Mais cela entra�ne quelques probl�mes, particuli�rement ceux qui
d�rivent des diff�rences de sensibilit�, voire des niveaux d�exigence, entre
les diff�rentes personnes qui exercent ce travail. C�est pour cette raison que
nous avons d�cid� de nous procurer un outil informatique qui puisse assurer une
plus grande objectivit� de l'observation �les m�mes ph�nom�nes pour tout le
monde, avec adaptation � la phon�tique utilis�e par chacun, ce qui veut dire
aussi une m�me exigence pour tout le monde. Pour le moment, cela n'est pas
possible avec le traitement des fichiers de voix, � cause des difficult�s
rencontr�es dans l'exploitation des syst�mes de reconnaissance de la voix, et
du grand nombre de voix � observer (plus de trois cents). Disons que le cerveau
humain est encore plus rapide que les syst�mes �lectroniques pour identifier
les correspondances entre un son et sa repr�sentation dans l�orthographe. Mais
il est possible d�envisager, pour les
programmes de radio bas�s sur la lecture de textes �qui, dans les quatre
stations de Catalunya R�dio, arrivent � presque 35 heures par jour� un outil
bas� sur le texte lu. C�est le DOPO.
2. DOPO:
l�outil
DOPO est un syst�me de d�tection d'incidents orthologiques
assist� par ordinateur. Il est bas� sur la synchronisation des fichiers de voix
et de texte. Cette synchronisation est faite par le programme SINCRO, qui sert
de base � tous les documents int�gr�s dans le corpus RETOC, qui a �t� pr�sent�
dans la communication pr�c�dente[1].
Une fois r�alis�e la synchronisation, le DOPO pr�sente � l'�cran des rapports
en forme d'hypertexte qui contiennent le texte �crit coup� en morceaux entre
pauses, de fa�on qu�en cliquant sur le texte l'orthologue peut �couter, le
nombre de fois qu'il veut, le fragment de voix correspondant et contr�ler ainsi
la correction et sa r�alisation phon�tique
Ces rapports hypertextuels peuvent �tre cr��s � deux
niveaux:
2.1. � partir de
la synchronisation par segments. La synchronisation exige toujours un
certain degr� d�intervention humaine pour en assurer la justesse. Quand la
synchronisation entre le texte el la voix est faite par morceaux entre deux
signes de ponctuation, elle est moins ch�re � la production, mais plus co�teuse
� l� exploitation, puisque l�orthologue doit �couter � chaque fois des morceaux
plus ou moins longs.
Voici l��cran qui va se pr�senter � l�orthologue dans ce
type de synchronisation:
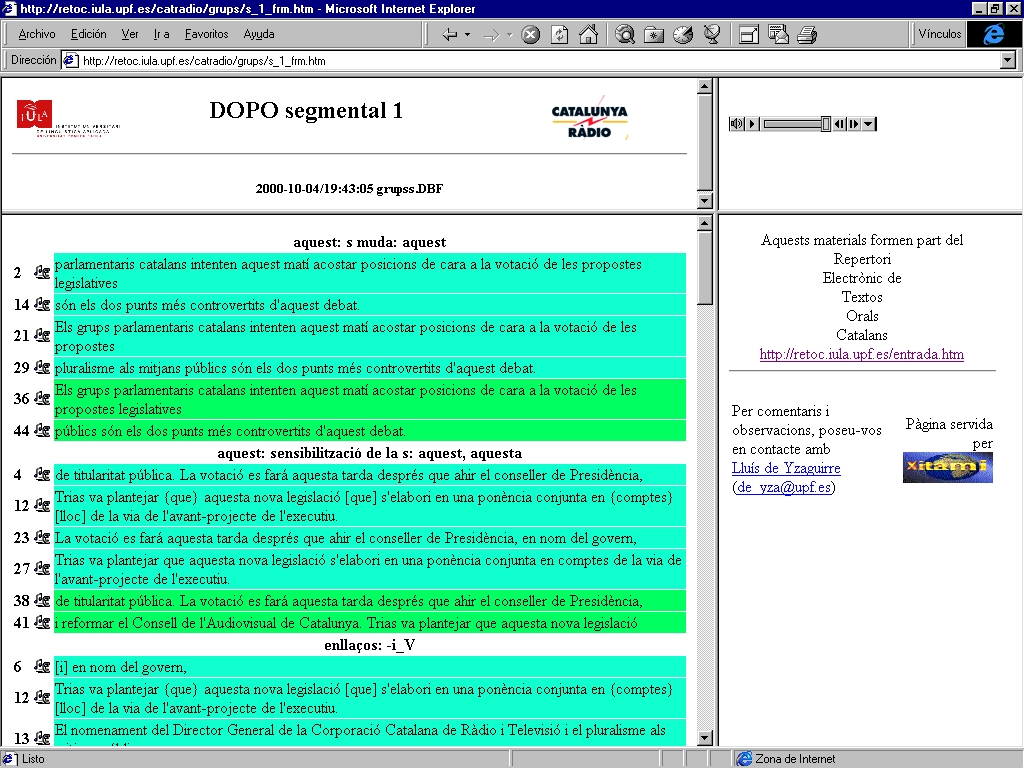
Au milieu de l��cran, nous voyons les fragments de texte
analys�s et � droite le num�ro du registre. En cliquant sur l�ic�ne
"musicale" de droite, nous pouvons �couter le morceau tel qu�il a �t�
prononc�.
2.2. � partir de
la synchronisation mot � mot. A l�inverse de la synchronisation par
morceaux, la synchronisation mot � mot exige beaucoup plus de temps
d�intervention humaine que l�ant�rieure (neuf fois plus), mais la consultation
peut �tre six fois plus rapide. Voici l'�cran qui va �tre pr�sent� �
l'orthologue:

Comme nous pouvons observer � l��cran, dans ce cas le texte
est s�par� lexicalement, et les mots sont ordonn�s alphab�tiquement. Chaque mot
peut �tre �cout� tout seul en cliquant sur l'ic�ne de gauche; accompagn� du mot
suivant, en cliquant sur celle du milieu, et, en cliquant sur celle de droite,
dans le morceau auquel il appartient, ce qui assure la possibilit� d�observer
le contexte, qui est important surtout dans les cas de contact de mots.
M�me s�il est possible de d�velopper les deux types de
synchronisation, pour l�instant nous ne nous sommes propos� de travailler
qu�avec la synchronisation par morceaux, � cause du co�t de temps qu�exige la
synchronisation mot � mot, m�me si celle-ci est tr�s int�ressante. Dans de
prochaines versions du programme nous avons le projet d�arriver � une
synchronisation automatique mot � mot.
3. Le
corpus de textes de radio
Afin d��prouver et de pr�senter le DOPO, nous avons constitu�
un corpus de huit heures de radio. Pour rendre possible leur traitement par le
DOPO, nous avons besoin en m�me temps de la version �crite et parl�e de chaque
morceau. Pour cette raison, il n'est pas possible d'inclure dans le corpus, des
discours spontan�s ou improvis�s, comme par exemple des morceaux de magasines,
interviews, etc., � moins que nous ne voulions les transcrire, ce qui
obligerait � des heures de travail que nous ne voulons� pas assumer pour le moment, � cause de leur
co�t. Donc, nous avons d�cid� de rassembler un corpus de nouvelles (qui ont une
importante base �crite qui n'arrive pas cependant non plus, � couvrir la
totalit� du discours).
Comme il a �t� d�j� dit, la surveillance sur le langage
utilis� en antenne doit respecter les principales vari�t�s de la langue. En
effet, l�Institut d'Estudis Catalans (l'Acad�mie catalane) �tablit que le
standard du catalan doit �tre "compositionnel", c'est � dire, qu'il
doit int�grer les principaux dialectes, ce qui veut dire que chaque speaker
doit utiliser les traits phon�tiques et morphologiques d'un seul d�entre eux,
sans les m�langer, tandis qu'on peut utiliser des unit�s lexicales et des
constructions syntaxiques telles que locutions et tours emprunt�s � d�autres
dialectes et devenus ainsi communs. Pour cette raison, nous avons d�cid�
d'inclure dans notre corpus des informations prononc�es avec la phon�tique des
deux grandes vari�t�s (orientale et occidentale) du catalan standard. Nous
avons choisi le poste Catalunya Informaci�, qui programme des informations
vingt-quatre heures sur vingt-quatre, parce que, gr�ce � la structure de sa
programmation en demie-heures, il est possible d'en extraire des demie-heures
cons�cutives prononc�es dans chacune de ces deux phon�tiques. Nous avons charg�
le speaker occidental de copier, pendant huit jours, les textes d'une de ses
demie-heures et de la pr�c�dente ou de la suivante, et de laisser ces copies �
l'ordinateur. Ensuite, nous avons r�cup�r� les fichiers de texte et les
fichiers de voix correspondants, et nous les avons envoy�s par courrier
�lectronique � Llu�s de Yzaguirre, pour en faire la synchronisation dont il
vient de vous parler. Les demie-heures cons�cutives ont l'avantage d'offrir des
informations tr�s semblables (le monde ne change pas si vite) dans deux
phon�tiques diff�rentes, ce qui facilite la comparaison et, le cas �ch�ant,
�conomise la transcription de certains morceaux enregistr�s qui sont
int�ressants et qui apparaissent dans les deux blocs mais qui n'ont pas de
texte �crit, de fa�on que le corpus analys� soit ainsi plus complet.
4. Filtres
de recherche
Avec la synchronisation toute seule, il serait n�cessaire
d'�couter tous les morceaux pour y d�tecter les erreurs. Alors, pour faciliter
la t�che de l'orthologue, on applique au texte coup� et synchronis� des filtres
qui s�lectionnent les s�quences de caract�res o� l'on soup�onne des
possibilit�s d'erreur.
Les filtres � appliquer sur le corpus doivent �tre utiles
pour d�tecter des erreurs, des prononciations inad�quates, etc. Ces filtres
auraient un fort contraste avec un filtre acad�mique: celui-ci s'int�resserait
� tous les ph�nom�nes, notamment � ceux qui sont corrects, suivant la structure
des grammaires scolaires; dans ce cas, les erreurs seraient une scorie �
rejeter. Mais quand le but de la recherche est de corriger ou de s�lectionner
le personnel, ce qui int�resse sont les erreurs, et les bonnes prononciations
sont scorie. Laissez-moi dire, cependant, que m�me si � pr�sent nous avons une
orientation et nous travaillons dans le but de d�tecter des erreurs, l'ensemble
des filtres peut �tre modifi� pour utiliser le DOPO comme outil� �ducatif ou de recherche.
4.1. Conventions
utilis�es dans les conditions de d�tection
Au moment d��tablir les formalismes des conditions de
d�tection, nous avons adopt� une s�rie de conventions qui sont explicit�es
ensuite:
4.1.1. Chaque cha�ne de caract�res sera cherch�e en
tant que telle dans n�importe quelle position dans le mot ou le segment. La
recherche va �tre faite sans distinction entre majuscules et minuscules.
4.1.2. Dans une recherche mot � mot, les seuls signes
non alphab�tiques cherch�s seront l�apostrophe (�), le tiret (-), le point haut
(�) et le point bas entre des l (l�l,
l.l). La synchronisation mot � mot ne s�pare pas les pronoms proclitiques ni
les articles et les pr�positions apostroph�s du mot qui accompagnent, parce
qu�ils constituent une seule unit� phonique. C�est pourquoi ces trois signes
sont aussi pris en compte dans la recherche.
4.1.3. Le point-virgule (;) et le signe plus (+)
servent � agglutiner diverses conditions dans une seule description.
4.1.4. Pour �tablir des conditions bas�es sur des
cat�gories phon�tiques telles que voyelle ou consonne, nous acceptons quatre
syst�mes de codification:
V: n�importe quelle voyelle, tonique ou atone, ainsi que le h suivi de voyelle.
C: n�importe quelle consonne.
R: n�importe quelle consonne sourde.
N: n�importe quelle consonne sonore.
4.1.5. Le signe de di�se (#) sert � marquer le blanc
entre mot et mot.
4.1.6. Il y a un certain nombre de cas dans lesquels la
recherche ne se fait pas � partir des conditions, mais � partir des listes de
mots difficiles. Dans ce cas, dans la base de donn�es du filtre il appara�t un
nom de fichier entre crochets. L�utilisation de listes de mots aide � �liminer
des �bruits�: en effet, la recherche bas�e sur des s�quences relativement
courtes de lettres peut entra�ner come r�sultat un plus grand nombre de mots
qui contiennent ces s�quences, mais qui sont prononc�s correctement, tandis que
les listes ne cherchent que les mots tout entiers, ce qui fait diminuer le
nombre des r�sultats.
4.1.7. Remarques
En utilisant des conditions de d�tection r�dig�es suivant
ces conventions, int�gr�es dans une base de donn�es, nous pouvons chercher une
lettre ou un groupe de lettres entre voyelles, entre voyelle et consonne, entre
consonnes (avec distinction entre consonnes sourdes et sonores), au d�but ou �
la fin du mot, et m�me le contact de sons de mots diff�rents, en substituant le
blanc entre les mots par le di�se.
Ce syst�me est bas� sur l�orthographe, et concerne seulement
le catalan. Cela peut entra�ner quelques probl�mes: par exemple, si le
programme trouve des mots provenant d�autres langues, il se peut que certaines
consonnes sourdes apparaissent comme sonores. C�est le cas, par exemple, du nom
espagnol Gonz�lez (o� les z sont interdentales sourdes). Ou,
encore, nous avons assign� au x la
cat�gorie de sourd, malgr� le fait qu�il puisse repr�senter des sons sourds ou
sonores selon sa position (par exemple: exacte
/ expulsat).
Au cours des �preuves r�alis�es avec les filtres nous avons
observ� aussi qu�il faut ajouter � ces conditions de recherche, d�une part, la
distinction entre les voyelles a, e, o,
d�un c�t�, et i, u, de l�autre, parce
qu�elles ont un comportement diff�rent dans les liaisons, notamment dans celles
marqu�es par l�apostrophe; et d�autre part une condition d�exclusion, pour
rendre possible le fait de pr�senter s�par�ment certains digraphes qui �
pr�sent apparaissent englob�s dans d�autres conditions et en m�me temps dans
leur propre filtre. C�est le cas, par exemple, du digraphe ix, qui appara�t aussi dans la condition VxV;� et du ss
double, qui appara�t dans les conditions VssV et CsV. Cette condition
d�exclusion servirait aussi � �viter l�apparition dans les r�sultats de
certains mots tr�s fr�quents qui sont toujours bien prononc�s . C�est le cas,
par exemple, de la pr�position per
qui appara�t souvent dans la condition de recherche destin�e au -r final, qui est d�ailleurs tr�s
int�ressante � cause des diff�rences de prononciation qui se produisent de
cette consonne en position finale entre diff�rents dialectes o� m�me �
l�int�rieur de ceux-ci.
4.2. Crit�res
pour l'�tablissement de conditions de d�tection
Les filtres que nous avons mis au point, et que nous sommes
en train de r�-�laborer pour mieux les adapter � notre travail, sont bas�s sur
la fr�quence des erreurs et sur leur importance. Importance du point de vue symbolique, par l'opposition qui
diff�rencie certains sons des langues voisines, notamment de l'espagnol; et
aussi importance du point de vue fonctionnel,
qui veut tenir compte de tous les ph�nom�nes de la langue.
Par exemple, en catalan nous avons la pr�sence du phon�me [�] lat�ral palatal sonore, (par exemple: palla, llengua, bullit, cavall) qui ne se trouve pas en fran�ais et
qui est en voie de disparition dans l�espagnol actuel. Ce phon�me devient donc
important pour l�image phonique de notre langue et constitue un des points cl�s
pour la s�lection des speakers. Cependant, les r�alisations incorrectes de ce
phon�me en [y] n�entra�nent
pas de probl�mes de compr�hension. Il s�agit, donc, surtout, d�un ph�nom�ne de
nature symbolique. Conserver le phon�me lat�ral palatal sonore signifie
conserver une diff�rence du catalan par rapport aux langues voisines.
D�autre part, il y a l'opposition entre s sourd [s]
et s sonore [z], qui n'est pas significative en espagnol, o� il n'y a des s sonores que par phon�tique syntaxique.
Le s sonore est donc une originalit�
du catalan, en contexte espagnol, et caract�rise fortement notre langue: en ce
sens il a une importance symbolique. En m�me temps, l'opposition entre s sonore et s sourd est pertinente pour la signification des mots (par exemple,
l� opposition typique entre casa
'maison' et ca�a 'chasse'): en ce
sens la bonne r�alisation des s a une
importance fonctionnelle. M�me si en g�n�ral une grande majorit� des speakers
r�alise correctement ce phon�me dans le mot, il arrive souvent qu�ils le
prononcent sourd dans les liaisons des mots. Cela, dans tous les dialectes.
Mais il y a des ph�nom�nes qui n'appartiennent qu'� une des
vari�t�s phon�tiques. C'est le cas, par exemple, de la neutralisation des a et e
atones en [2] et les
r�ductions des o et u atones � [u] dans la phon�tique orientale. Il y a aussi des ph�nom�nes
nettement occidentaux qui ne sont pas observables en contexte oriental. Par
exemple, l'ouverture de beaucoup d'e
initiaux en [a] (escolta � [as'kolte]),
ou la "fermeture" du a
final en [e] � la
troisi�me personne de l�indicatif pr�sent (p. ex., ce m�me mot).
Pour la m�me raison de vocalisme propre � chaque variante,
les ph�nom�nes de contact de voyelles dans le mot n'offrent aucun probl�me
important dans l'occidental, tandis que dans l'oriental � chaque contact de
voyelles il est possible d'observer des r�alisations diverses, plus ou moins
neutralis�es ou r�duites qui d�pendent souvent de la fr�quence d�apparition du
mot, c�est � dire, de l�habitude de dire certains mots. L�usage �use� les mots
et les am�ne � la neutralisation; les mots moins habituels sont prononc�s avec
moins de neutralisation, plus �� la lettre�.
D�autre part, l�absence d�usage formel et public de la
langue catalane pendant des d�cennies, a provoqu� un manque de tradition, qui,
ajout� � la volont� de tr�s bien parler , conduit les jeunes speakers � des
prononciations exag�r�es, qui dans le catalan oriental tendent � un exc�s de
neutralisation, vu comme un �loignement de l�espagnol. Par exemple, ils peuvent
oublier que les mots compos�s conservent les deux accents d�origine, ce qui
dans le catalan oriental signifie la prononciation non neutralis�e de deux
syllabes dans le m�me mot. Par exemple, dans les num�ros: tres-cents, trenta-vuit (souvent prononc� [tr�s'sens tr�nt�'bujt] � la place de [trEs'sens trEnt�'bujt]).; ou dans n�importe quel mot compos�: portaveu (souvent prononc� [purt�'bEw] � la place de [p�rt�'bEw]).
Tous ces ph�nom�nes r�clament des filtres sp�cifiques pour
chacune des deux vari�t�s principales, en ce qui concerne le vocalisme, parce
qu'il n'est pas op�ratif d'appliquer un filtre bas� sur le vocalisme oriental �
une voix occidentale, et vice-versa. Il est, donc, important d'affiner les
filtres afin d��viter l�obtention d�un certain nombre de r�sultats non
significatifs, ainsi que l�oubli de certains ph�nom�nes.
Cela nous a amen�s � ajouter � la base de donn�es une zone
num�rique additionelle, appel�e NIVELL, qui doit permettre d�appliquer
s�lectivement les filtres selon le cas: par exemple, dans la s�lection des
voix, il est important de passer en premier lieu des filtres tr�s �l�mentaires,
comme ceux du l palatal [�] ou du s sonore [z] qui �tant syst�matiques, sont plus difficiles � corriger
que les quelques mots �difficiles� inclus dans une liste. Nous avons num�rot�
ces cha�nes de conditions de recherche, ainsi qu�un certain nombre de
ph�nom�nes consonantiques communs aux deux vari�t�s principales, avec un 1.
Ensuite, les conditions de recherche sur le vocalisme ont �t� num�rot�es 2 pour
le vocalisme oriental, et 3 pour l�occidental. Compte tenu que les filtres
bas�s sur des listes de mots difficiles ne recueillent pas un grand nombre
d�occurrences � chaque application, nous les avons tous laiss�s au niveau 4.
Finalement, nous avons num�rot� 5 les filtres portant sur des ph�nom�nes moins
fr�quents, ou qui sont importants seulement en vue d�une locution excellente.
4.3. Structure
de la base de donn�es
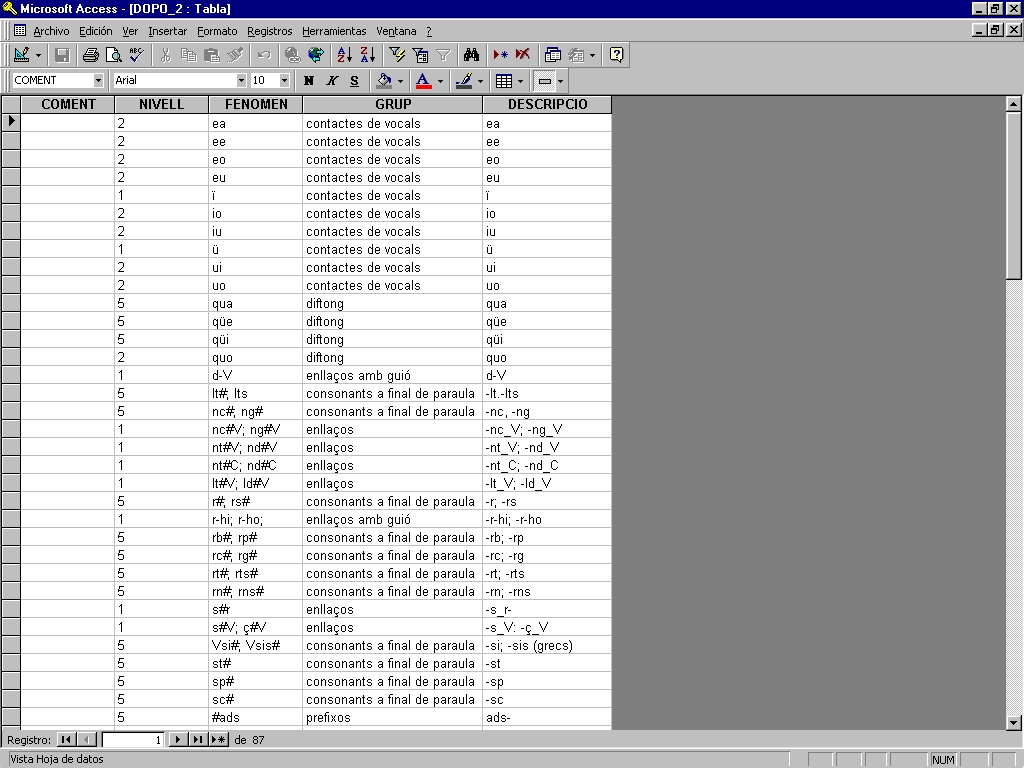
Les conditions de recherche des ph�nom�nes � observer sont
formalis�es par des formules comme celles dont nous venons de parler, et
plac�es dans une base de donn�es � 5 zones:
COMENT: Cette zone contient un commentaire standard de chaque
ph�nom�ne observ�. Ces commentaires peuvent �tre associ�s � un rapport en
hypertexte adress� au speaker observ�. Ils peuvent servir aussi � la formation
des orthologues, puisqu'ils peuvent les guider dans l'observation. Ils
contiennent toujous la description de la prononciation correcte propos�e.
NIVELL: Zone qui contient les num�ros dont nous avons parl� avant.
Ces num�ros nous permettent d'appliquer s�lectivement certains groupes de
conditions � chaque voix, et d'�viter ainsi l'obtention de r�sultats non
significatifs. Vous trouverez ces diff�rents groupes de filtres appliqu�s un
par un, puis� tous ensemble, sur chacun
des fichiers de voix trait�s par le DOPO dans le corpus RETOC-Corpus 2000 de
Catalunya R�dio � l'adresse http://retoc.iula.upf.es.
Cette application s�lective de niveaux de filtre permet
aussi de porter l'observation � des degr�s diff�rents selon les besoins. Par
exemple, dans une s�lection de speakers on peut appliquer en premier une s�rie
�l�mentaire de filtres, qui serviront � faire une premi�re s�lection, qui peut
�tre suffisante: tous les candidats accept�s remplissent les m�mes conditions
minimum. Il est possible alors d'appliquer un deuxi�me degr� de s�lection avec
un filtre plus fin (d�un niveau plus haut). La somme de tous les filtres sera
aussi appliqu�e aux speakers qui ont plus de pr�sence � l'antenne, pour r�viser
de temps en temps la qualit� de leur langage. Avec ce syst�me nous pourrons
m�me v�rifier la qualit� de la langue utilis�e � l� antenne, collectivement, au
bout de quelques ann�es.
FENOMEN: Zone qui contient la formalisation des ph�nom�nes �
observer, en utilisant les conventions d�crites dans l'alin�a ant�rieur.
DESCRIPCIO et GRUP sont des
zones descriptives � des niveaux diff�rents, pr�vus pour la pr�sentation des
r�sultats dans les rapports hypertextuels: DESCRIPCIO contient strictement une
r�f�rence au ph�nom�ne observ�, tandis que GRUP g�n�ralise cette description
afin de pouvoir grouper les observations: par exemple, �liaisons�, ou
�consonnes en fin de mot� ou �pr�fixes�. Les r�sultats de l�application des
filtres sont pr�sent�s � l'�cran ordonn�es par GRUP et DESCRIPCIO.
Ensuite, nous pr�sentons quelques incidences orthologiques
avec les conditions r�dig�es selon les conventions ant�rieures, et plac�es dans
la base de donn�es.
5. Conclusions
�La UAL (service
linguistique) de Catalunya R�dio envisage d�int�grer l�usage effectif du DOPO
dans son travail habituel, quand l�application de la phase SINCRO sera � peu
pr�s automatis�e.
Le DOPO pourra alors �tre utilis� pour:
-Assurer une plus grande objectivit� de la s�lection
linguistique des voix.
-Syst�matiser la veille sur la qualit� phon�tique des
�missions.
-Cr�er des rapports hypertextuels individualis�s sur le
langage des speakers, en vue d�am�liorer, s�il le faut, leur prononciation. Ces
m�mes rapports pourront �tre utilis�s dans des cours de formation de speakers.
-Pr�parer des orthologues qui vont faire la veille
linguistique des �missions, puisqu�il peut leur pr�senter un r�pertoire complet
(ou presque complet) des ph�nom�nes qu�ils doivent observer.
-Observer le degr� de fid�lit� au texte lu ou le degr� de
cr�ativit� dans la communication. Observer en m�me temps si cette cr�ativit�
�loigne les speakers de la correction.
-V�rifier l��volution r�elle, � l��chelle collective, de la
prononciation du catalan standard utilis� � la radio, dans ses diff�rentes
vari�t�s, au cours des ann�es.
Avec une adaptation dels filtres actuels, le DOPO peut �tre
utile aussi pour l�enseignement du catalan, notamment dans les universit�s
�trang�res, puisqu�il
offre la possibilit� de faire �couter aux �l�ves la r�alisation effective de
tous les sons de la langue. Dans ce cas bien s�r, et � l�inverse de ce qui se
passe lors de� son utilisation � la
radio, il faut rejetter les erreurs.
�